Projection uncertainty
Table of Contents
After a calibration has been computed, it is essential to get a sense of how good the calibration is (how closely it represents reality). Traditional calibration routines rely on one metric of calibration quality: the residual fit error. This is clearly inadequate because we can always improve this metric by throwing away input data, and it doesn't make sense that using less data would make a calibration better.
There are two main sources of error in the calibration solve. Without these errors, the calibration data would fit perfectly, producing a solve residuals vector that's exactly \(\vec 0\). The two sources of error are:
- Model errors. These result when the solver's model of the world is insufficient to describe what is actually happening. Examples of this are motion blur, unsyncronized cameras, too-simple lens models, imperfect chessboard geometry, chessboard detector errors, instability in lens behavior or chessboard shape, and so on. Since these errors aren't modeled, we can't analytically predict their effects, and these errors cannot be eliminated completely. But we have tools to detect and correct some of these issues. We can take care when gathering data, and then we can check that these errors aren't significant.
- Sampling error. This is the error in the input data. We cannot eliminate this completely either, but we can define a reasonable model of the noise, and we can propagate it analytically to gauge its effect.
The mrcal projection uncertainty analysis studies the effect of sampling error. Since only the sampling error is evaluated:
any promises of a high-quality low-uncertainty calibration are valid only if the model errors are small.
So it's important to run the checks to make sure that the data fits the model well.
The method to estimate the projection uncertainty is accessed via the
mrcal.projection_uncertainty() function. Here the "uncertainty" is the
sensitivity to sampling error: the calibration-time pixel noise. This tells us
how good a calibration is (we aim for low projection uncertainties), and it
tells us how good the downstream results are (by allowing the user to propagate
projection uncertainties through their data pipeline).
To estimate the projection uncertainty we:
- Estimate the noise in the chessboard observations
- Propagate that noise to the optimal parameters \(\vec b^*\) reported by the calibration routine
- Propagate the uncertainty in calibration parameters \(\vec b^*\) through the projection function to get uncertainty in the resulting pixel coordinate \(\vec q\)
This overall approach is sound, but it implies some limitations:
- Only the response to chessboard observation noise is taken into account. Other sources of error are not included in the reported uncertainty. Issues such as motion blur, out-of-synchronization images, unexpected chessboard shape as not included. It is thus imperative that we try to minimize these errors, and mrcal provides tools to detect these.
- The choice of lens model affects the reported uncertainties. Lean models (those with few parameters) are less flexible than rich models, and don't fit general lenses as well as rich models do. This stiffness also serves to limit the model's response to noise in their parameters. Thus the above method will report less uncertainty for leaner models than rich models. So, unless we're sure that a given lens follows some particular lens model perfectly, a splined lens model (i.e. a very rich model) is recommended for truthful uncertainty reporting. Otherwise the reported confidence comes from the model itself, rather than the calibration data.
- Currently the uncertainty estimates can be computed only from a vanilla calibration problem: a set of stationary cameras observing a moving calibration object. Other formulations can be used to compute the lens parameters as well (structure-from-motion while also computing the lens models for instance), but at this time the uncertainty computations cannot handle those cases. It can be done, but the current method needs to be extended to do so.
Estimating the input noise
We're measuring the sensitivity to the noise in the calibration-time observations. In order to propagate this noise, we need to know what that input noise is. The current approach is described in the optimization problem formulation.
Propagating input noise to the state vector
We solved the least squares problem, so we have the optimal state vector \(\vec b^*\).
We apply a perturbation to the observations \(\vec q_\mathrm{ref}\), reoptimize this slightly-perturbed least-squares problem, assuming everything is linear, and look at what happens to the optimal state vector \(\vec b^*\).
We have
\[ E \equiv \left \Vert \vec x \right \Vert ^2 \] \[ J \equiv \frac{\partial \vec x}{\partial \vec b} \]
At the optimum \(E\) is minimized, so
\[ \frac{\partial E}{\partial \vec b} \left(\vec b = \vec b^* \right) = 2 J^T \vec x^* = 0 \]
We perturb the problem:
\[ E( \vec b + \Delta \vec b, \vec q_\mathrm{ref} + \Delta \vec q_\mathrm{ref})) \approx \left \Vert \vec x + \frac{\partial \vec x}{\partial \vec b} \Delta \vec b + \frac{\partial \vec x}{\partial \vec q_\mathrm{ref}} \Delta \vec q_\mathrm{ref} \right \Vert ^2 = \left \Vert \vec x + J \Delta \vec b + \frac{\partial \vec x}{\partial \vec q_\mathrm{ref}} \Delta \vec q_\mathrm{ref} \right \Vert ^2 \]
And we reoptimize:
\[ \frac{\mathrm{d}E}{\mathrm{d}\Delta \vec b} \approx 2 \left( \vec x + J \Delta \vec b + \frac{\partial \vec x}{\partial \vec q_\mathrm{ref}} {\Delta \vec q_\mathrm{ref}} \right)^T J = 0\]
We started at an optimum, so \(\vec x = \vec x^*\) and \(J^T \vec x^* = 0\), and thus
\[ J^T J \Delta \vec b = -J^T \frac{\partial \vec x}{\partial \vec q_\mathrm{ref}} {\Delta \vec q_\mathrm{ref}} \]
As defined on the input noise page, we have
\[ \vec x_\mathrm{observations} = W (\vec q - \vec q_\mathrm{ref}) \]
where \(W\) is a diagonal matrix of weights. These are the only elements of \(\vec x\) that depend on \(\vec q_\mathrm{ref}\). Let's assume the non-observation elements of \(\vec x\) are at the end, so
\[ \frac{\partial \vec x}{\partial \vec q_\mathrm{ref}} = \left[ \begin{array}{cc} - W \\ 0 \end{array} \right] \]
and thus
\[ J^T J \Delta \vec b = J_\mathrm{observations}^T W \Delta \vec q_\mathrm{ref} \]
So if we perturb the input observation vector \(q_\mathrm{ref}\) by \(\Delta q_\mathrm{ref}\), the resulting effect on the optimal parameters is \(\Delta \vec b = M \Delta \vec q_\mathrm{ref}\) where
\[ M = \left( J^T J \right)^{-1} J_\mathrm{observations}^T W \]
As usual,
\[ \mathrm{Var}(\vec b) = M \mathrm{Var}\left(\vec q_\mathrm{ref}\right) M^T \]
As stated on the input noise page, we're assuming independent noise on all observed pixels, with a standard deviation inversely proportional to the weight:
\[ \mathrm{Var}\left( \vec q_\mathrm{ref} \right) = \sigma^2 W^{-2} \]
so
\begin{aligned} \mathrm{Var}\left(\vec b\right) &= \sigma^2 M W^{-2} M^T \\ &= \sigma^2 \left( J^T J \right)^{-1} J_\mathrm{observations}^T W W^{-2} W J_\mathrm{observations} \left( J^T J \right)^{-1} \\ &= \sigma^2 \left( J^T J \right)^{-1} J_\mathrm{observations}^T J_\mathrm{observations} \left( J^T J \right)^{-1} \end{aligned}If we have no regularization, then \(J_\mathrm{observations} = J\) and we can simplify even further:
\[\mathrm{Var}\left(\vec b\right) = \sigma^2 \left( J^T J \right)^{-1} \]
Note that these expressions do not explicitly depend on \(W\), but the weights still have an effect, since they are a part of \(J\). So if an observation \(i\) were to become less precise, \(w_i\) and \(x_i\) and \(J_i\) would all decrease. And as a result, \(\mathrm{Var}\left(\vec b\right)\) would increase, as expected.
Propagating the state vector noise through projection
We now have the variance of the full optimization state \(\vec b\), and we want to propagate this through projection to end up with an estimate of uncertainty at any given pixel \(\vec q\).
The state vector \(\vec b\) is a random variable, and we know its distribution. To evaluate the projection uncertainty we want to project a fixed point, to see how this projection \(\vec q\) moves around as the chessboards and cameras and intrinsics shift due to the uncertainty in \(\vec b\). In other words, we want to project a point defined in the coordinate system of the camera housing, as the origin of the mathematical camera moves around inside this housing:

How do we operate on points in a fixed coordinate system when all the coordinate systems we have are floating random variables? We use the most fixed thing we have: chessboards. As with the camera housing, the chessboards themselves are fixed in space. We have noisy camera observations of the chessboards that implicitly produce estimates of the fixed transformation \(T_{\mathrm{cf}_i}\) for each chessboard \(i\). The explicit transformations that we actually have in \(\vec b\) all relate to a floating reference coordinate system: \(T_\mathrm{cr}\) and \(T_\mathrm{rf}\). That coordinate system doesn't have any physical meaning, and it's useless in producing our fixed point.
Thus if we project points from a chessboard frame, we would be unaffected by the untethered reference coordinate system. So points in a chessboard frame are somewhat "fixed" for our purposes.
To begin, let's focus on just one chessboard frame: frame 0. We want to know the uncertainty at a pixel coordinate \(\vec q\), so let's unproject and transform \(\vec q\) out to frame 0:
\[ \vec p_{\mathrm{frame}_0} = T_{\mathrm{f}_0\mathrm{r}} T_\mathrm{rc} \mathrm{unproject}\left( \vec q \right) \]
We then transform and project \(\vec p_{\mathrm{frame}_0}\) back to the imager to get \(\vec q^+\). But here we take into account the uncertainties of each transformation to get the desired projection uncertainty \(\mathrm{Var}\left(\vec q^+ - \vec q\right)\). The full data flow looks like this, with all the perturbed quantities marked with a \(+\) superscript.
\[ \vec q^+ \xleftarrow{\mathrm{intrinsics}^+} \vec p^+_\mathrm{camera} \xleftarrow{T^+_\mathrm{cr}} \vec p^+_{\mathrm{reference}_0} \xleftarrow{T^+_{\mathrm{rf}_0}} \vec p_{\mathrm{frame}_0} \xleftarrow{T_\mathrm{fr}} \vec p_\mathrm{reference} \xleftarrow{T_\mathrm{rc}} \vec p_\mathrm{camera} \xleftarrow{\mathrm{intrinsics}} \vec q \]
This works, but it depends on \(\vec p_{\mathrm{frame}_0}\) being "fixed". We can do better. We're observing more than one chessboard, and in aggregate all the chessboard frames can represent an even-more "fixed" frame. Currently we take a very simple approach towards combinining the frames: we compute the mean of all the \(\vec p^+_\mathrm{reference}\) estimates from each frame. The full data flow then looks like this:
\begin{aligned} & \swarrow & \vec p^+_{\mathrm{reference}_0} & \xleftarrow{T^+_{\mathrm{rf}_0}} & \vec p_{\mathrm{frame}_0} & \nwarrow & \\ \vec q^+ \xleftarrow{\mathrm{intrinsics}^+} \vec p^+_\mathrm{camera} \xleftarrow{T^+_\mathrm{cr}} \vec p^+_\mathrm{reference} & \xleftarrow{\mathrm{mean}} & \vec p^+_{\mathrm{reference}_1} & \xleftarrow{T^+_{\mathrm{rf}_1}} & \vec p_{\mathrm{frame}_1} & \xleftarrow{T_\mathrm{fr}} & \vec p_\mathrm{reference} \xleftarrow{T_\mathrm{rc}} \vec p_\mathrm{camera} \xleftarrow{\mathrm{intrinsics}} \vec q \\ & \nwarrow & \vec p^+_{\mathrm{reference}_2} & \xleftarrow{T^+_{\mathrm{rf}_2}} & \vec p_{\mathrm{frame}_2} & \swarrow \end{aligned}This is better, but there's another issue. What is the transformation relating the original and perturbed reference coordinate systems?
\[ T_{\mathrm{r}^+\mathrm{r}} = \mathrm{mean}_i \left( T_{\mathrm{r}^+\mathrm{f}_i} T_{\mathrm{f}_i\mathrm{r}} \right) \]
Each transformation \(T\) includes a rotation matrix \(R\), so the above constructs a new rotation as a mean of multiple rotation matrices, which is aphysical: the resulting matrix is not a valid rotation. In practice, the perturbations are tiny, and this is sufficiently close. Extreme geometries do break it, and this will be fixed in the future.
So to summarize, to compute the projection uncertainty at a pixel \(\vec q\) we
- Unproject \(\vec q\) and transform to each chessboard coordinate system to obtain \(\vec p_{\mathrm{frame}_i}\)
- Transform and project back to \(\vec q^+\), useing the mean of all the \(\vec p_{\mathrm{reference}_i}\) and taking into account uncertainties
We have \(\vec q^+\left(\vec b\right) = \mathrm{project}\left( T_\mathrm{cr} \, \mathrm{mean}_i \left( T_{\mathrm{rf}_i} \vec p_{\mathrm{frame}_i} \right) \right)\) where the transformations \(T\) and the intrinsics used in \(\mathrm{project}()\) come directly from the optimization state vector \(\vec b\). So
\[ \mathrm{Var}\left( \vec q \right) = \frac{\partial \vec q^+}{\partial \vec b} \mathrm{Var}\left( \vec b \right) \frac{\partial \vec q^+}{\partial \vec b}^T \]
We computed \(\mathrm{Var}\left( \vec b \right)\) earlier, and \(\frac{\partial \vec q^+}{\partial \vec b}\) comes from the projection expression above.
The mrcal.projection_uncertainty() function implements this logic. For the
special-case of visualizing the uncertainties, call the any of the uncertainty
visualization functions:
mrcal.show_projection_uncertainty(): Visualize the uncertainty in camera projectionmrcal.show_projection_uncertainty_vs_distance(): Visualize the uncertainty in camera projection along one observation ray
or use the mrcal-show-projection-uncertainty tool.
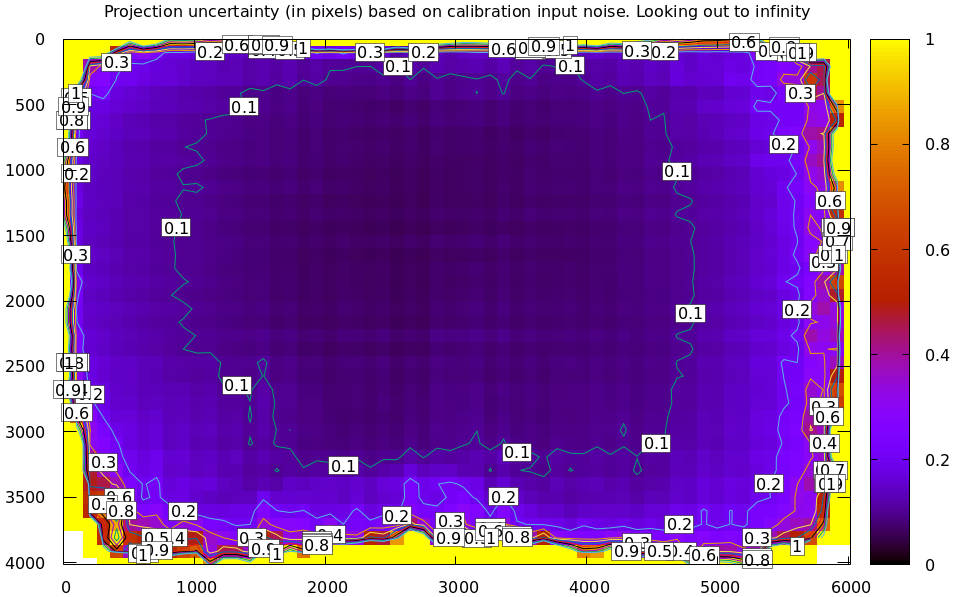
A sample uncertainty map of the splined model calibration from the tour of mrcal looking out to infinity:
mrcal-show-projection-uncertainty splined.cameramodel --cbmax 1 --unset key
The effect of range
We glossed over an important detail in the above derivation. Unlike a projection operation, an unprojection is ambiguous: given some camera-coordinate-system point \(\vec p\) that projects to a pixel \(\vec q\), we have \(\vec q = \mathrm{project}\left(k \vec v\right)\) for all \(k\). So an unprojection gives you a direction, but no range. The direct implication of this is that we can't ask for an "uncertainty at pixel coordinate \(\vec q\)". Rather we must ask about "uncertainty at pixel coordinate \(\vec q\) looking \(x\) meters out".
And a surprising consequence of that is that while projection is invariant to scaling (\(k \vec v\) projects to the same \(\vec q\) for any \(k\)), the uncertainty of projection is not invariant to this scaling:

Let's look at the projection uncertainty at the center of the imager at different ranges for an arbitrary model:
mrcal-show-projection-uncertainty \ --vs-distance-at center \ --set 'yrange [0:0.1]' \ opencv8.cameramodel

So the uncertainty grows without bound as we approach the camera. As we move away, there's a sweet spot where we have maximum confidence. And as we move further out still, we approach some uncertainty asymptote at infinity. Qualitatively this is the figure I see 100% of the time, with the position of the minimum and of the asymptote varying.
As we approach the camera, the uncertainty is unbounded because we're looking at the projection of a fixed point into a camera whose position is uncertain. As we get closer to the origin, the noise in the camera position dominates the projection, and the uncertainty shoots to infinity.
The "sweet spot" where the uncertainty is lowest sits at the range where we observed the chessboards.
The uncertainty we asymptotically approach at infinity is set by the specifics of the chessboard dance.
See the tour of mrcal for a simulation validating this approach of quantifying uncertainty and for some empirical results.